Publication conventions
5-star Linked Open Data
Title: 5-star Linked Open Data |
Identifier PC-R1 |
Statement: Publishing data specifications shall be compliant with 5-star LOD criteria. |
Description:
Publishing a vocabulary as a Linked Open Data (LOD) resource means making it accessible, both human and machine-readable, in a standard way, thus supporting the semantic web. The publication as full LOD implies that the data is compliant with the highest grade of 5-Star [5star-od] open data evaluation:
-
The data is available on the Web under an open licence
-
The data is available following a clear structure
-
The data is available using a non-proprietary open format
-
The data uses URIs to denote concepts
-
The data is linked to other resources to provide context
On the same note, the FAIR Data Principles [fair-principles] is a more comprehensive and rich set of guidelines for publishing data on the web. They ensure the Findability, Accessibility, Interoperability and Reuse of digital assets. The principles emphasise machine-actionability (i.e., the capacity of computational systems to find, access, interoperate, and reuse data with none or minimal human intervention) because humans increasingly rely on computational support to deal with data, as a result of the increase in volume, complexity and creation speed of data [fair-guidelines].
Persistent URI policy
Title: Persistent URI policy |
Identifier PC-R2 |
Statement: The URIs that are used to identify the terms modelled in the data specifications should be dereferenceable Persistent URIs [10rules-puri] and comply with a URI policy (or URI strategy). URIs that are well-defined according to such criteria are often denoted as PURIs [10rules-puri]. SEMIC adheres to the EU persistent URI policy. Each SEMIC URI is dereferenceable in both machine representation (RDF artefacts) and human-readable (HTML artefact). |
Description:
When publishing data on the web [dwdp], it is crucial to have a structured and persistent system of URIs in place. Such URIs make it easy for the users to understand the vocabulary structure and retrieve information as they expect.
The 10 rules for Persistent URIs [10rules-puri] are base principles for the design of quality identifiers. Regarding URI design, the main consideration of creators should be that when a URI is created, all its parts should be resistant to change. For instance, locations and organisation names can change and therefore should not be used in URIs. First and foremost, when introducing semantics in URIs, the strings used need to reflect what the resources are (i.e. intrinsic characteristics such as the type or nature), not who owns them or where they are [uri-dp].
In 2014, the ISA Programme devised a common policy for managing persistent HTTP-based URIs of EU institutions [uri-dp, 10rules-puri, puri-gov-eu]. That has led to an EU wide URI resolution service, prescribing that each URI is of the following pattern:
The {Collection} is an organisation-agnostic name for a collection of terms. Within a {Collection} the local names, or
references, are being maintained according to the policy of the {Collection}. For SEMIC data specifications, the names
are dependent on the naming conventions mentioned in this style guide rules [GC-R4 + CMC-R3].
Version management
Title: Version management |
Identifier PC-R3 |
Statement: A consistent version management shall be implemented for the data specification evolution respecting the "semantic versioning" principles. |
Description:
The SEMIC versioning methodology is based on "semantic versioning" principles [sem-ver] and implements a simple set of rules and requirements that dictate how version numbers are assigned and incremented. It involves describing clearly and precisely what is being published and which features are included, and what the limitations are, setting the expectations and scope. Once the artefacts are identified for the public, the changes to the data specifications are communicated with specific increments to the version number and with associated change notes.
The version format is X.Y.Z (Major.Minor.Patch).
As a rule of thumb, bug fixes do not affect the artefact and increment the Patch version. Backwards compatible artefact additions/changes increment the Minor version. And, backwards-incompatible artefact changes increment the Major version.
Examples:
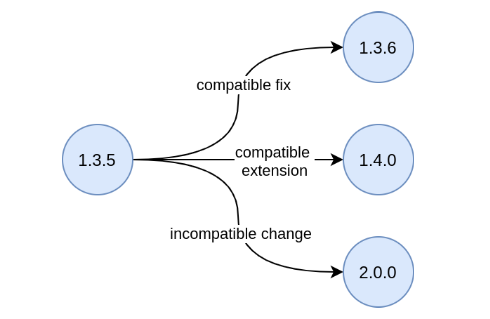
For example, evolving from version 1.3.5 to 1.3.6 represents a backwards-compatible patch, from 1.3.5 to 1.4.0, a backwards-compatible new development, while switching from 1.3.5 to 2.0.0 breaks the backwards compatibility.
Artefact versioning
Title: Artefact versioning |
Identifier PC-R4 |
Statement: The data specification shall be versioned as a whole and never to atomic elements (concepts, relations or constraints). |
Description:
Create a new version with each publication. Using the semantic version principles to determine the exact version number depends on whether it is a major, minor or patch update.
The version shall be assigned to the entire vocabulary or Application Profile and never to elements in the model
(concepts, relations, constraints, etc.) [oslo-rules, sec 3.1.6]. The version shall be saved as the model metadata
(for example, in the owl:Ontology header).
No version information shall be embedded into any artefact URIs unless it is a version URI provided via owl:versionIRI.
URI dereferencing
Title: URI dereferencing |
Identifier PC-R5 |
Statement: Any URI identifiable resource devised in a data specification shall be dereferenceable. |
Description:
Dereferencing means that one can use the URI as an URL to retrieve related information back. The format and representation in which the information is returned depend on content negotiation. Content negotiation is the interaction between the client application and the server in which the client informs the server about its preferred format and representation and the server responds with the best-fitting result it can provide.
It is recommended to provide (format) content negotiation for HTTP which is based on the interpretation of the Accept: HTTP header.
The dereferencing shall be provided for both human-readable and machine-readable formats. A human-aimed HTML representation is the default response (if no content type is specified), and the other is RDF [10rules-puri].
Because the HTML representation is usally a long document, which makes it hard to find the information about a specific term, it is recommended that the HTML representation has landing points based on the used fragment identifier. Dereferencing can then route the reader to the most relevant information within the HTML document.
For other representations/formats no additional requirements are imposed. For example, the dereferencing in the RDF representation, depends on the implemented recipe, i.e. based on # or /; and it may return either the corresponding fragment or the whole RDF document [pub-recipe].
Further technical details can be found in "Best Practice Recipes for Publishing RDF Vocabularies" [rdf-pub].
Human-readable form
Title: Human-readable form |
Identifier PC-R6 |
Statement: Each data specification shall have a corresponding human-readable form representing the model documentation. |
Description:
The documentation content shall follow a standard template for consistent formatting and content structuring.
It is a good practice to provide the following sections in the document:
-
Preamble with metadata indicating
-
Title
-
Abstract
-
Date of publication/release
-
Version information
-
Authors, editors, contributors
-
Licensing information
-
-
Introduction describing the
-
Background information
-
Context & Scope
-
Intended audience
-
UML diagrams of the model
-
-
Description of each element in the model grouped by element type (e.g. class, property, constraint, controlled vocabulary). Each element shall be described by its URI and its Lexicalisation:
-
URI (shall be clearly visible)
-
Labels (preferred and alternative)
-
Definitions, scope notes, examples, editorial notes, etc.
-
Moreover, consider following the good practices for documenting OWL 2 and SHACL artefacts, and include the appropriate details in the data specification documentation. For OWL 2, we can mention tools like Widoco [widoco] and LODE [lode]; and for SHACL, follow the SHACL recommendation [shacl], or the metadata support implemented in tools such as SHACL-play [shacl-play]. For application profiles, consider aligning to the DCAP [dcap], which is an implementation agnostic recommendation.