Introduction
This Handbook explains the role of Core Vocabularies in enabling semantic interoperability at the EU level and provides a practical guide for public administrations to use them. It is intended for business users who wish to understand how the Core Vocabularies can be useful, and for semantic engineers who seek straightforward guidance for specific use cases.
For first-time readers of this Handbook, we recommend starting with the remainder of this section, where interoperability is introduced, the role of Core Vocabularies is explained, and the important use cases are summarised.
Readers familiar with the SEMIC Core Vocabularies and seeking practical guidance are advised to go directly to the main part of the Handbook, which describes use cases, methodology recommendations, and tutorials for:
-
creating new semantic data specifications or stand-alone data models by using Core Vocabularies, and
-
mapping existing data models to Core Vocabularies.
Intended audience
This handbook is intended for two main audiences: 1) administrative professionals, including policy officers and possibly also legal experts, and 2) technical experts and IT professionals. Public administrations involve both legal/administrative experts and technical professionals. While they may not always “speak the same language”, they must work together to ensure smooth digital transformation. Semantic interoperability provides the common foundation that allows them to bridge their disciplinary differences and find common ground, enabling effective collaboration and thereby contributing to improved public services. Each intended audience will gain new insights relevant for their respective roles.
Administrative Professionals & Legal Experts
By reading this handbook, domain experts will:
-
Understand the role of semantic interoperability at the EU level, which might also be of use at the national, regional, and local level.
-
Gain insight about how structured data and shared vocabularies enhance legal clarity, data exchange, and cross-border cooperation.
-
Gain insights into how interoperability supports public services and reduces administrative burdens.
It is expected that this will facilitate coordination with technical teams to ensure that interoperability initiatives meet both legal and operational requirements and assist the administrative professionals and legal experts in making informed decisions prioritising IT projects that align with interoperability goals.
Technical Experts & IT Professionals
By engaging with this handbook as both a reference manual and a practical guide, the technical experts and IT professionals who design, implement, and maintain the software ecosystem will:
-
Learn how to design and implement interoperable systems using the Core Vocabularies and semantic data models.
-
Understand methodologies for creating, mapping, and integrating semantic data models in their systems.
-
Be able to apply best practices for data exchange, ensuring consistency and accuracy across different systems.
-
Use standardised approaches to enhance data accessibility, transparency, and reuse in line with FAIR principles [fair].
-
Ensure compliance with the SEMIC Style Guide rules & principles [sem-sg].
It is expected that this will not only facilitate communication with the domain experts, but also further streamline software development conformant to the user specification and, ultimately, the citizens who benefit from more smoothly functioning digital services.
Structure of the Handbook
The Handbook has two types of content:
-
Explanatory Sections: Intended for administrative professionals and legal experts. They explain interoperability, the role of Core Vocabularies, and describe relevant use cases. It helps non-technical stakeholders understand why semantic interoperability matters and how it supports policy implementation. Each use case is also accompanied by a business case scenario and a user story.
-
Practical Guidance Sections: Designed for technical experts, data architects, and IT professionals, which provide methodologies and step-by-step tutorials for adopting and implementing Core Vocabularies. It includes instructions on creating new semantic data specifications by extending Core Vocabularies, mapping existing data models to them, and ensuring interoperability through standardised practices.
The structure of the main part of the Handbook is as follows. First, the notion of interoperability and the principal use cases will be introduced, which feature the most common, challenging, and interesting scenarios. This is followed by two key chapters, on creating new models and on mapping existing models, which describe and illustrate the principal use cases. For each use case, there is a description intended for administrative professionals and legal experts, guidelines for implementation that describe procedures how to accomplish the goal of the use case, which are then demonstrated in the tutorial for the use case. The guidelines and tutorials are aimed at the technical experts.
Finally, the appendix contains a glossary of terms, additional use cases not covered in this handbook, and the references.
Interoperability and Core Vocabularies
This section introduces what interoperability is, what makes it semantic, and how Core Vocabularies–which is where key concepts are specified in human-readable and machine-processable formats–contribute to it.
Sharing data easily is indispensable for effective and efficient public services. Sharing may be done through offering one point of access, and often involves reusing the data in multiple applications across multiple departments and organisations. To make this work, the information systems need to be interoperable.
What is interoperability?
Following the European Interoperability Framework (EIF) [eif], interoperability is defined as “the ability of organisations to interact towards mutually beneficial goals, involving the sharing of information and knowledge between these organisations, through the business processes they support, by means of the exchange of data between their ICT systems”, where, for the purpose of EIF, ‘organisations’ refers to “public administration units or any entity acting on their behalf, or EU institutions or bodies”. It is what “enables administrations to cooperate and make public services function across borders, across sectors and across organisational boundaries”, including enabling “public sector actors to connect, cooperate and exchange data while safeguarding sovereignty and subsidiarity”, as described in the EC communication accompanying the Interoperable Europe Act [int-eu].
Existing acts and frameworks related to interoperability
The European Union has formulated Acts, regulations, and frameworks that intend to foster achieving that, including the Data Act [data-act], Data Governance Act [dga], the European Interoperability Framework (EIF) [eif], and the Interoperable Europe Act [iea24], which underscore the importance of harmonised data practices across member states. These Acts and frameworks emphasise that true interoperability goes far beyond just connecting systems at a technical level.
The EU Data Act is a legislative framework aimed at enhancing the EU’s data economy by improving access to data for individuals and businesses. It entered into force on January 11, 2024, and is designed to ensure fairness in data allocation and encourage data-driven innovation.
The Data Governance Act (DGA) is a regulation by the European Union aimed at facilitating data sharing and increasing trust in data usage. It establishes a framework for the reuse of publicly held data and encourages the sharing of data for altruistic purposes, while also regulating data intermediaries to enhance data availability and overcome technical barriers. The act is part of the broader European strategy for data, which seeks to create a more integrated and efficient data economy.
The EIF provides specific guidance on how to set up interoperable digital public services. It gives guidance, through a set of recommendations, to public administrations on how to improve governance of their interoperability activities, establish cross-organisational relationships, streamline processes supporting end-to-end digital services, and ensure that existing and new legislation do not compromise interoperability efforts.
The Interoperable Europe Act, which entered into force on 11 April 2024, aims to enhance cross-border interoperability and cooperation in the public sector across the EU. It is designed to support the objectives of the Digital Decade, ensuring that 100% of key public services are available online by 2030, including those requiring cross-border data exchange. The Act addresses challenges by creating tools for interoperability within public administrations and removing legal, organizational, and technical obstacles. It envisions an emerging ‘network of networks’ of largely sovereign actors at all levels of government, each with their own legal framework and mandates, yet all interconnected”, i.e., for seamless cross-border cooperation, which is to be supported by mandatory assessments.
What is semantic interoperability and how to achieve it?
While data exchange is an obvious requirement for interoperability, there are fine but crucial distinctions between data format, syntactic, and semantic interoperability. A standardised syntax and data format to store data lets one exchange data, such as creating an SQL database dump in one tool and seamlessly reopening it in another relational database management system, or lets one send and receive emails that arrive properly in each other’s inbox.
Interoperability at the semantic level concerns the meaning of that data. One may have the same format and language to represent data, such as XML, but with a tag <bank> … </bank>, neither the software nor the humans can determine from just that what sort of bank is enclosed within the tags. Such meaning is defined in various artefacts such as vocabularies, thesauri, and ontologies. A <fin:bank> tag in a document may then be an implemented version of its definition at the semantic layer, where the entity has a definition and a number of properties specified in the model (abbreviated with fin), like that the fin:bank is a type of financial organisation with a board of directors and has a location for its headquarters. This enables not only correct sending and receiving of data, but also exchanging data reliably, accessing the right data when querying for information, obtaining relevant data in the query answer, and merging data.
Interoperability thus consists of a semantic component as well, which "refers to the meaning of data elements and the relationship between them" and "includes developing vocabularies and schemata to describe data exchanges" [eif4scc]. According to the EIF, section 3.5 [eif2], semantic interoperability "ensures that the precise format and meaning of exchanged data and information is preserved and understood throughout exchanges between parties, in other words ‘what is sent is what is understood’." One recommended way to achieve semantic interoperability between public administrations is to use semantic assets, such as semantic data models, information models, ontologies, and vocabularies. SEMIC uses models called Core Vocabularies.
What is a Core Vocabulary?
A Core Vocabulary (CV) is a basic, reusable, and extensible specification that captures the relevant characteristics of entities, which can be used to add semantics to data and information in a context-neutral manner [cv-hb]. Its primary purpose is to provide standardised terms that can be reused across various application domains, typically realised as a lightweight ontology (optionally accompanied by a permissive data shape) and documented in a concise specification. Core Vocabularies for SEMIC [sem-sg-cvs] are maintained by the SEMIC action under the Interoperable Europe umbrella of DG DIGIT and are described in the SEMIC Core Vocabularies section below.
SEMIC Core Vocabularies
Since 2011, the European Commission has facilitated international working groups to forge consensus and maintain the SEMIC Core Vocabularies. A short description of these vocabularies is included in the Table below. The latest release of the SEMIC Core Vocabularies can be retrieved via the SEMIC Support Center [semic] or directly from the GitHub repository [semic-gh] in both human- and machine-readable formats. They are published under the CC-BY 4.0 licence [cc-by]. Henceforth, when we use the term Core Vocabularies, we refer to the SEMIC Core Vocabularies specifically.
| Vocabulary | Description |
|---|---|

|
The Core Person Vocabulary (CPV) [cpv] is a simplified, reusable and extensible vocabulary that captures the fundamental characteristics of a person; e.g., the name, gender, date of birth, and location. This specification enables interoperability among registers and any other ICT-based solutions exchanging and processing person-related information. |

|
The Core Business Vocabulary (CBV) [cbv] is a simplified, reusable and extensible vocabulary that captures the fundamental characteristics of a legal entity; e.g., the legal name, activity, and address. The Core Business Vocabulary includes a minimal number of classes and properties modelled to capture the typical details recorded by business registers. It facilitates information exchange between business registers despite differences in what they record and publish. |

|
The Core Location Vocabulary (CLV) [clv] is a simplified, reusable and extensible vocabulary that captures the fundamental characteristics of a location, represented as an address, a geographic name, or a geometry. The Location Core Vocabulary provides a minimum set of classes and properties for describing a location represented as an address, a geographic name, or a geometry. This specification enables interoperability among land registers and any other ICT-based solutions exchanging and processing location information. |

|
The Core Criterion and Core Evidence Vocabulary (CCCEV) [cccev] supports the exchange of information between organisations that define criteria and organisations that respond to these criteria by means of evidence. The CCCEV addresses specific needs of businesses, public administrations and citizens across the EU, including the following use cases:
|

|
The Core Public Organisation Vocabulary (CPOV) [cpov] provides a vocabulary for describing public organisations in the European Union. It addresses specific needs of businesses, public administrations and citizens across the European Union, including the following use cases:
|

|
The Core Public Event Vocabulary (CPEV) [cpov] is a simplified, reusable and extensible vocabulary that captures the fundamental characteristics of a public event, e.g., the title, the date, the location, the organiser etc. It aspires to become a common model for describing public events (conferences, summits, etc.) in the European Union. This specification enables interoperability among registers and any other ICT based solutions exchanging and processing information related to public events. |

|
The Core Public Service Vocabulary Application Profile (CPSV-AP) [CPSV-AP] is a vocabulary for describing public services and the associated life and business events. With the CPSV-AP it is possible to:
|
The Core Vocabularies are semantic data specifications [sem-sg-wsds] that are disseminated as the following artefacts:
-
lightweight ontology [sem-sg-wio] for vocabulary definition expressed in OWL [owl2];
-
loose data shape specification [sem-sg-wds] expressed in [shacl];
-
human-readable reference documentation [sem-sg-wdsd] in HTML (based on ReSpec [respec]);
-
conceptual model specification [sem-sg-wcm] expressed in UML Class Diagram notation [uml].
Why Core Vocabularies?
Modern-day information system design has moved the goalposts, notably that they typically have to operate in an ecosystem of tools and data, which caused a number of new problems, notably:
-
Developers are reinventing the wheel by modelling the same topics over and over again in different organisations, which is a wasteful use of time and other resources.
-
Consequent near-duplications and genuine differences cause, at best, delays in interoperability across systems and, at worst, legally inconsistent data, thereby harming individuals or organisations.
-
A lack of a high-level common vocabulary causes engineers to create many 1:1 low-level technical mappings between resources that are buried in implementations, which become an unmaintainable mesh structure the more new resources are added and the more often the sources are updated.
-
Individual formats of published datasets require more ad hoc Extract-Transform-Load scripts to reuse commonly reused data, such as cadaster data and registries of companies, imposing a higher burden on tool developers to create and maintain the data processing scripts.
Core vocabularies contribute to the solution of all these problems at once thanks to providing agreed-upon shared common building blocks in commonly used domains, such as public services, events, persons and more. Core Vocabularies can be used as, as formulated on the SEMIC Support Centre site:
-
a starting point for designing the conceptual data models and application profiles for newly developed information systems, simply through reuse of the terminology;
-
the basis of a particular data model that is used to exchange data among existing information systems;
-
common model to integrate data originating from disparate data sources thanks to the shared terminology;
-
the foundation for defining a common export format for data and thereby facilitating the development of common import mechanisms.
Concretely, let us illustrate the problem versus the solution for languages designed for interoperability, such as XML. The XSD schema and the corresponding XML files that adhere to it help achieve syntactic interoperability for those XML files. It does not achieve interoperability among the XSD schemas, however, because there is no such mechanism to declare that a tag in schema xs1, say, <bank> is the same as <bank> in schema xs2. We need another mechanism to achieve that, which is provided by vocabularies that operate at a higher level of abstraction to which the XSD schemas can be linked: the semantic layer.
Alternatively, one can avoid the interoperability problem by creating multiple XSD schemas from the same vocabulary which then offers semantic interoperability implicitly. When a developer wants to reuse a Core Vocabulary-based XSD, they only can be used as-is or extended into a more specific application profile, but not modified to the extent that it could to contradict the Core Vocabulary, thereby continuing to foster the intended interoperability.
In addition, with Core Vocabularies represented in RDFS or OWL, one can mix vocabularies and link to external concepts, whereas that is not possible with XSD where only types and elements defined in the single schema can be used.
Finally, an added benefit is that while multilingual XSD is possible through manually created tags to store the multilingual information, such features are already part of standardised vocabulary languages used by the Core Vocabularies, such as SKOS, RDF, RDFS, and OWL, thereby offering a standardised approach to multilingual labels, which facilitates software development, reuse, and interoperability.
Core Vocabularies lifecycle
The SEMIC Core Vocabularies have been developed following the ‘Process and methodology for developing Core Vocabularies’ [cv-met] of which the most relevant section is depicted in the figure below. Assuming stakeholders and Working Group members with relevant roles are in place, requirements are defined, which are thoroughly assessed on existing standardisation efforts, evidence, and other data models. When a change is deemed necessary, it enters a drafting phase that focuses on the technical details whilst adhering to the SEMIC Style Guide, followed by public consultations. Thereafter, if deemed necessary based on the feedback, it will undergo another modelling iteration, else the changes are refined and the model finalised. The final model is formally approved, implemented, and documented, ensuring they are well-understood and agreed upon by all relevant parties.
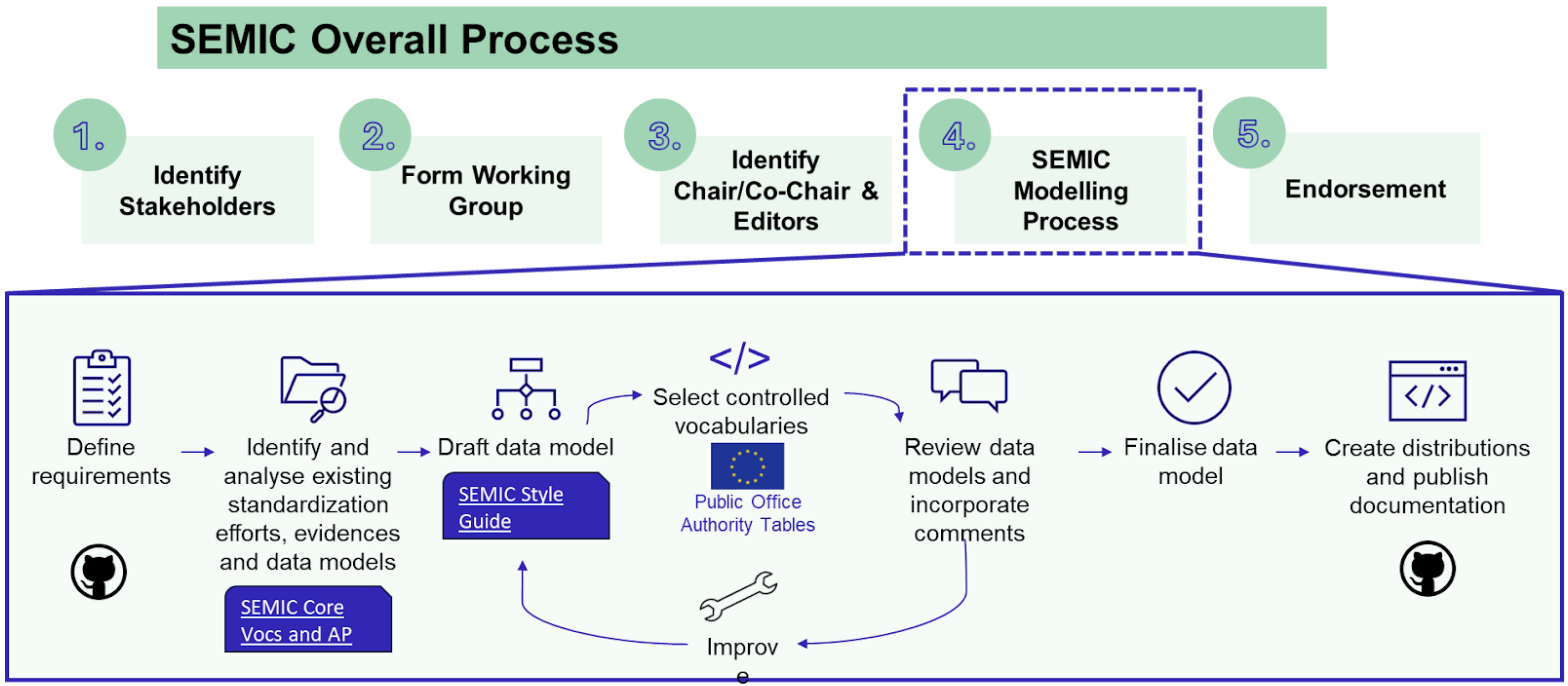
The release management of Core Vocabularies follows a structured timeline for all tasks and each release includes detailed documentation to support implementation, so that users can integrate new versions with minimal disruption. This process maintains the quality and relevance of the Core Vocabularies, and supports a dynamic and responsive framework for semantic interoperability within digital public services.
Overview of use cases for using Core Vocabularies
Let us commence with a practical example that contributes to setting the stage for defining the use cases afterward.
A practical example
Imagine you are starting a business in another EU country. To complete the registration, you need to submit a criminal record certificate and a diploma certificate to multiple public organisations. In many countries, this process is still manual—people must physically visit different ministries, request documents, and submit them in person or via email. Each organisation may use different formats and terminology, making it difficult for institutions to interpret and process the information correctly. This can generate mistakes during data entry due to terminological confusion that subsequently have to be corrected. Without a common reference vocabulary, these organisations interpret the data differently, making seamless exchange impossible.
Now, imagine an alternative scenario, such as indicated by the Once-Only Technical System (OOTS) [oots] for the Single Digital Gateway Regulation [sdgr], where this entire process is fully automated. Instead of individuals having to visit multiple offices, the ministries and public administrations would communicate directly with each other, exchanging the necessary information in a structured and consistent manner. The citizen could simply grant approval to the administration office to fetch the data from their home country that already had recorded the relevant data. This would eliminate the need for data re-submission by citizens (according to the once-only principle) and for duplicate document submissions, as well as avoid possible data entry issues and thereby making evidence verification faster. Overall, achieving this degree of data interoperability can considerably reduce burdens for citizens and public administrations in terms of hassle, costs, and mobility.
Defining the what is one step; the how to achieve it is another.
How to solve the scenario with semantic data specifications
How can different systems and institutions "talk" to each other effectively at the level of software applications and the various types of databases? That technical level uses data models to structure the stored data. This first raises the questions of who is developing those data models, and how, and then how those different data models across the database and applications agree on the terminology used in them. Therefore, the challenge is not only technical but also semantic. It is not enough for systems to simply exchange data—they must also be able to interpret the meaning behind the data in a consistent way such that it will not result in errors or so-called 'dirty' (incorrect or incomplete) data. This requires a common language and a (multilingual) structured vocabulary at both the business process level and the IT systems level.
This is where standards to declare the semantics play a crucial role. By using Core Vocabularies, public administrations can ensure that data and information are structured in a way understood by both humans and machines. Standardised models allow different organisations to recognise and process information without discrepancies, thereby reducing errors and the need for manual intervention. As a result, governments can facilitate seamless data exchange, ensuring that information is accurately expressed, shared, interpreted, and processed across systems, leading to more efficient approvals and interactions for businesses, governmental organisations, and citizens.
These vocabularies can then be used by the IT personnel of the various departments to create their data models, thereby in effect avoiding incompatibility by building interoperability into the systems from the start. But what about existing systems from, e.g., a Ministry of Economic Affairs, a national Chamber of Commerce, and other organisations that are relevant to the Single Digital Gateway? Setting aside existing systems to build a new one may not be reasonable and cost effective, especially when they already have their own entrenched terminologies embedded into them or have already incorporated other models used internationally, such as Schema.org or the Financial Business Industry Ontology. There is a solution to that problem, too: map the specifications at this semantic layer to make the other model interoperable with the CV and then use both through that declared mapping ‘bridge’ between them.
It is these two key ways of using CVs that will be covered in the use cases: creating new data specifications availing of the CVs (possibly adding one’s own additional content to it) and mapping existing schemas.
Introduction to the use cases covered in the handbook
This handbook serves as a practical guide for using Core Vocabularies in various common situations. To provide clear and actionable insights, we have categorised potential use cases into two groups:
-
Primary Business and Technical Use Cases: These are the most common, interesting, and/or challenging scenarios, all thoroughly covered within this handbook.
-
Additional Business and Technical Use Cases: These briefly introduce other relevant scenarios but are not elaborated on in detail in this handbook.
A business case in the current context is to be understood as a narrative user story (in terms of the technical expert terminology), which functions as motivation for the use case. They capture the who, what, and why in a broader context, including who the beneficiary of an action is, what they need, and what the benefit of it is. Such a narrative is then structured into a user story as a structured sentence that captures the essence of the business case yet also communicates genericity. For the technical reader, a use case specification is listed afterwards, which provides a schematic view as a step towards the precise technical specifications.
We differentiate between use cases focussed on the creation of new artefacts and those involving the mapping of existing artefacts to Core Vocabularies. For better clarity, we numbered the use cases and organised them into two diagrams, one for the primary scenarios (see Figure 2, below) and the other for depicting the additional ones. The former are addressed in the main part of this handbook, whereas the latter are listed in the Appendix and may be elaborated on at a later date if there is a demand from the community.
The use cases are written in white-box point of style oriented towards user goals following Cockburn’s classification [uc-book]. We will use the following template to describe the relevant use cases:
Use Case <UC>: Title of the use case |
Goal: A succinct sentence describing the goal of the use case |
Primary Actor: The primary actor or actors of this use case |
Actors: (Optional) Other actors involved in the use case |
Description: Short description of the use case providing relevant information for its understanding |
Example: An example to illustrate the application of this use case |
Note: (Optional) notes about this use case, especially related to its coverage in this handbook |
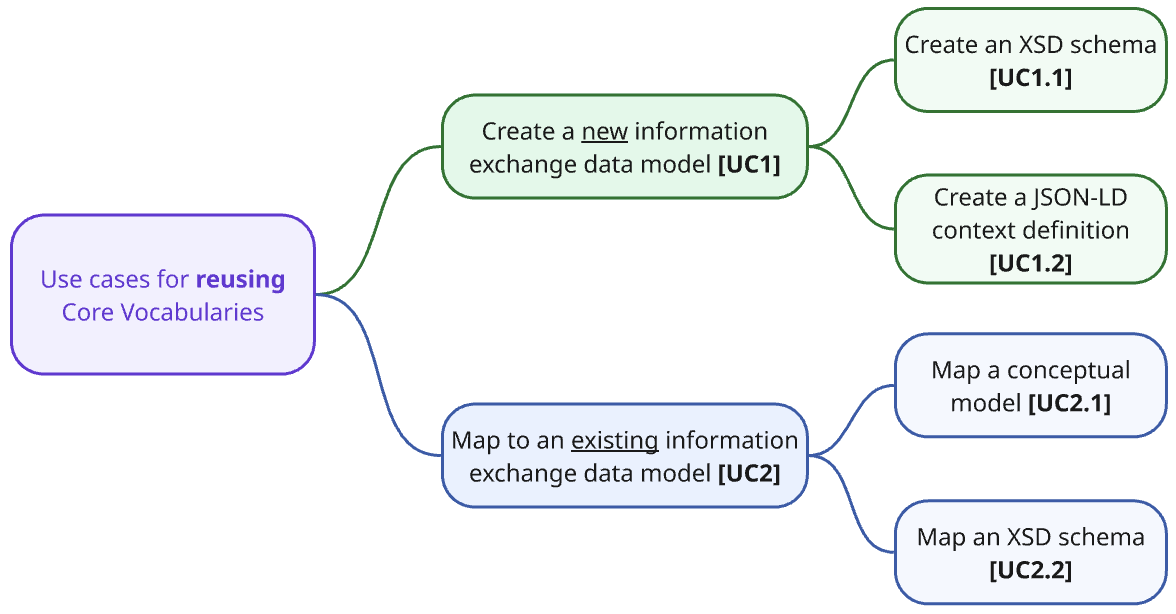
The use cases described below serve as a quick-access overview; complete concrete scenarios are introduced in the respective dedicated section’s “Description” section.
UC1: Create a new model from a Core Vocabulary
For creating new models, there are two business cases for illustration. In short:
-
UC1.1: Jean-Luc from the Maltese Chamber of Commerce who wants to create an XML schema (XSD) by using the Core Business Vocabulary (CBV), so that he reduces design time and ensures consistent, interoperable, and standards-compliant e-form validation across government systems.
-
UC1.2: Nora from the Norwegian Digitalisation Task Force who needs to provide guidance to the City of Oslo to create a new JSON-LD context based on the Core Public Services Vocabulary Application profile (CPSV-AP). This way, the City can create smart data models compliant with national and European interoperability standards and publish linked data for cross-system data exchange.
The main use case UC1 is summarised as follows, which is subsequently refined into two more specific cases.
Use Case UC1: Create a new information exchange data model |
Goal: Create a new standalone data schema that uses terms from Core Vocabularies. |
Primary Actors: Semantic Engineer, Software Engineer |
Description: The goal is to design and create a new data schema or information exchange data model that is not part of a more comprehensive semantic data specification, relying on terms from existing CVs as much as possible. |
Note: As this is a more generic use case it will be broken down into concrete use cases that focus on specific data formats. |
Use Case UC1.1: Create a new XSD schema |
Goal: Create a new standalone XSD schema that uses terms from Core Vocabularies. |
Primary Actors: Semantic Engineer, Software Engineer |
Description: The goal is to design and create a new XSD schema that is not part of a more comprehensive semantic data specification, relying on terms from existing CVs as much as possible. As an information exchange data model, an XSD schema can be used to create and validate XML data to be exchanged between information systems. |
Example: OOTS XML schema mappings [oots] |
Note: A detailed methodology to be applied for this use case will be provided in the Create a new XSD schema section. |
Use Case UC1.2: Create a new JSON-LD context definition |
Goal: Create a new standalone JSON-LD context definition that uses terms from Core Vocabularies. |
Primary Actors: Semantic Engineer, Software Engineer |
Description: The goal is to design and create a new JSON-LD context definition that is not part of a more comprehensive semantic data specification, relying on terms from existing CVs as much as possible. As an information exchange data model, a JSON-LD context definition can be integrated in describing data, building APIs, and other operations involved in information exchange. |
Example: Core Person Vocabulary [cpv-json-ld], Core Business Vocabulary [cbv-json-ld] |
Note: A detailed methodology to be applied for use cases will be provided in the Create a new JSON-LD context definition section. |
UC2: Map an existing model to a Core Vocabulary
For mapping vocabularies, there are two business cases for illustration. In short:
-
UC2.1: Sofía with the Department of Agriculture’s outreach division wants to map her existing conceptual model about outreach events that already uses the Core Business Vocabulary (CBV) and align it with Schema.org. This way, the event data can be distributed across the interoperable Europe and global web vocabularies, enabling a wider reach of accurate data exchange.
-
UC2.2.: Ella, working for the National Registry of Certified Legal Practitioners, wants to map her existing XML Schema Definition (XSD) to the Core Business Vocabulary (CBV). This enables her to transform the XML data into semantically enriched RDF such that it complies with European interoperability standards and supports linked data publication, and thereby enabling cross-system data exchange.
The main use case UC2 is summarised as follows, which is subsequently refined into two specific ones. They serve as a quick overview; concrete scenarios are introduced in the dedicated “Description” section.
Use Case UC2: Map an existing data model to a Core Vocabulary |
Goal: Create a mapping of an existing (information exchange) data model, to terms from Core Vocabularies. |
Primary Actors: Semantic Engineer |
Actors: Domain Expert, Software Engineer |
Description: The goal is to design and create a mapping of an ontology, vocabulary, or some kind of data schema or information exchange data model that is not part of a more comprehensive semantic data specification, to terms from CVs. Such a mapping can be done at a conceptual level, or formally, e.g., in the form of transformation rules, and most often will include both. |
Note: Since this is a more generic use case it will be broken down into concrete use cases that focus on specific data models and/or data formats. Some of those use cases will be described in detail below, while others will be included in the Appendix with the additional use cases. |
Use Case UC2.1: Map an existing Ontology to a Core Vocabulary |
Goal: Create a mapping between the terms of an existing ontology and the terms of Core Vocabularies. |
Primary Actors: Semantic Engineer |
Actors: Domain Expert, Business Analyst, Software Engineer |
Description: The goal is to create a formal mapping expressed in Semantic Web terminology (for example using rdfs:subClassOf, rdfs:subPropertyOf, owl:equivalentClass, owl:equivalentProperty, owl:sameAs properties), associating the terms in an existing ontology that defines relevant concepts in a given domain, to terms defined in one or more CVs. This activity is usually performed by a semantic engineer based on input received from domain experts and/or business analysts, who can assist with the creation of a conceptual mapping. The conceptual mapping associates the terms in an existing ontology, which defines relevant concepts within a specific domain, to terms defined in one or more SEMIC Core Vocabularies. The result of the formal mapping can be used later by software engineers to build information exchange systems. |
Example: Mapping Core Person to Schema.org [map-cp2org], Core Business to Schema.org [map-cb2org], etc. |
Note: A detailed methodology to be applied for this use case will be provided in the Map an existing Model section. |
Use Case UC2.2: Map an existing XSD schema to a Core Vocabulary |
Goal: Define the data transformation rules for the mapping of an XSD schema to terms from Core Vocabularies. Create a mapping of XML data that conforms to an existing XSD schema to an RDF representation that conforms to a Core Vocabulary for formal data transformation. |
Primary Actors: Semantic Engineer |
Actors: Domain Expert, Business Analyst, Software Engineer |
Description: The goal is to create a formal mapping using Semantic Web technologies (e.g. RML or other languages), to allow automated translation of XML data conforming to a certain XSD schema, to RDF data expressed in terms defined in one or more SEMIC Core Vocabularies. This use case required definitions of an Application Profile for a Core Vocabulary because the CV alone does not specify sufficient instantiation constraints to be precisely mappable. |
Example: ISA2core SAWSDL mapping [isa2-map] |
Note: A detailed methodology to be applied for this use case will be provided in the Map an existing XSD schema section. |
The additional use cases are described in the Appendix.