Creating a new data model from an existing Core Vocabulary
Technologies rise and decline in popularity, yet one of the red threads through the computational techniques over the decades is the management of structured data. Data needs to be stored, processed, acted upon, shared, integrated, presented, and more, all mediated by software. This also means that the structure of the data needs to be machine-readable far beyond the simple scanned hard-copy administrative forms or legal documents. Structured data mediates between entities in the real world and their representation in the software.
For instance, to represent the fact “govtDep#1 subcontracts comp#2”, we might have
-
a table with government departments that also contains a row with govtDep#1;
-
a table with companies and their identifying data including comp#2; and
-
a table with subcontracting relationships between instances, including (GovtDep#1,Comp#2).
A mechanism to capture the sort of structured and semi-structured data which may be stored and managed in the system is called a data model at the level of the technical implementation and conceptual data model or vocabulary as part of a semantic data specification when it is implementation-independent. Such models represent the entity types, such as GovernmentDepartment, Company, and its more generic type Organisation from our example, along with relationships between entity types, such as Subcontracting. Data models typically also implement business rules or constraints that apply to the particular organisation. For instance, one rule might state that each government department is permitted to subcontract at most 15 companies in country#3 whereas there may be no upper bound to subcontracting in country#4 and a prohibition on subcontracting (i.e., is permitted to subcontract at most 0) in country#5. These variations require different data models or application profiles, although they may use the same vocabulary.
This raises a number of questions:
-
What sort of data models are there?
-
Who develops those models?
-
How do they develop the models?
-
How can we ensure that those models are interoperable across applications and organisations, so that the data is interoperable as a consequence of adhering to those model specifications?
There are a number of languages to declare data models, which are normally developed by data modellers and database designers. While they may develop a data model from scratch, increasingly, they try to reuse existing specifications to speed up the development and foster interoperability. For use case 1, we address these questions from the perspective of creating new data models that reuse Core Vocabularies, either in full or in part, depending on the specific needs. In this chapter we focus on creating two types of data models: XSD schemas and JSON-LD contexts.
Each model type has its business case providing a rationale why one would want to do this, which is described in the respective “Use case description” sections. The respective “Guidelines” sections then walk the reader through the creation process (addressing mixed technical and non-technical audience), and finally the respective “Tutorial” sections target technical staff with a step-by-step example that implements the guideline.
Create a new XSD schema from a Core Vocabulary (UC1.1)
Use case description
We will introduce the motivation for the use case with a user story.
Imagine Jean-Luc, a semantic/software engineer assigned to develop a software application for processing online forms for the Maltese Chamber of Commerce. Among the format options of online forms are Office365, CSV, and XML that each have their pros and cons. Jean-Luc chooses XML, since many other forms are already being stored in XML format.
He is aware that XML files should have a schema declared first, which contains the specifications of the sort of elements and fields that are permitted to be used in the forms, such as the company’s registration number, name, and address. However, analysing the data requirements from scratch is not the preferred option. Moreover, there are Chambers of Commerce in other EU countries, which use forms to collect and update data. Perhaps he could reuse and adapt those schemas?
As Jean-Luc starts to search for existing models, called XML schemas in XSD format, he realises there are other places where businesses need to submit forms with company information, such as online registries and the tax office, that also may have XSD files available for reuse.
Unfortunately, not one of them made their schema available.
Given that such availability would be useful also at the EU level, he looks for guidance at the EU level. He finds The SEMIC Core Business Vocabulary, which has terminology he can reuse, not only saving time developing his own XSD schema but then also making it interoperable with all other XSD schemas that reuse the vocabulary.
User story: As a semantic engineer working in public sector IT, I want to create an XML schema (XSD) by reusing elements from the existing Core Business Vocabulary (CBV), so that I can reduce design time and ensure consistent, interoperable, and standards-compliant e-form validation across government systems.
The business case translates into the following use case specification, which is instantiated from the general UC1.1 description in the previous section:
Use Case UC 1.1: Create a new XSD schema |
Goal: Create a new XSD schema for e-forms from the Core Business Vocabulary. |
Primary Actors: Semantic Engineer |
Description: Design and create a new XSD schema for the Maltese chamber of commerce, reusing as much as possible from the Core Business Vocabulary. This new schema is to be used principally to validate e-forms, and possibly to exchange or collect data from other software systems. |
Having established the who, what, and why, the next step is how to accomplish this. An established guideline of good practice for XSD Schema development from a vocabulary is consulted to guide the process. This guideline is described in the next section.
Guidelines to create a new XSD schema
This section provides detailed instructions for addressing use case UC1.1. To create a new XSD schema, the following main steps need to be carried out:
-
Import or define elements
-
Shape structure with patterns
-
Validation
This is visualised in the following figure, together with key tasks and suggestions.
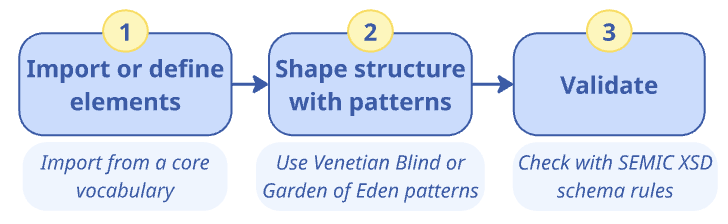
Phase 1: Import or define elements
When working with XML schemas, particularly in relation to semantic artefacts like ontologies or data shapes, managing the imports and namespaces are vital considerations that ensure clarity, reusability, and proper integration of various data models.
When a Core Vocabulary has defined an associated XSD schema, it is not only easy but also advisable to directly import this schema using the xsd:import statement. This enables seamless reuse and guarantees that any complex types or elements defined within the Core Vocabulary are integrated correctly and transparently within new schemas.
The imported elements are then employed in the definition of a specific document structure. For example, Core Vocabularies are based on DCTERMS that provides an XML schema, so Core Person could import the DCTERMS XML schema for the usage of a concept.
In cases where the Core Vocabulary does not provide an XSD schema, it is necessary to create the XML element definitions in the new XSD schema corresponding to the reused URIs. Crucially, these new elements must adhere to the namespace defined by the Core Vocabulary to maintain consistency; for the Core Vocabularies, they must be defined within the http://data.europa.eu/m8g/ namespace.
Furthermore, when integrating these elements into a new schema, it is essential to reflect the constraints from the Core Vocabulary’s data shape—specifically, which properties are optional and which are mandatory–within the XSD Schema element definitions.
|
Reusing elements and types from the Core Vocabulary improves interoperability and alignment with EU data standards, yet also imposes some limitations. Since reuse occurs at the syntactic level, element names and structures, including complex types, from the Core Vocabulary can be extended, but not easily restricted (for instance, limiting Organization to a single sub-organization would require creating a new complex type). These trade-offs between semantic interoperability and technical consistency are discussed in the Why Core Vocabularies section. |
Phase 2: Shape XML document structure
In designing XML schemas, the selection of a design pattern has implications for the reusability and extension of the schema. The Venetian Blind and Garden of Eden patterns stand out as preferable for their ability to allow complex types to be reused by different elements [dsg-ptr].
The Venetian Blind pattern is characterised by having a single global element that serves as the entry point for the XML document, from which all the elements can be reached. This pattern implies a certain directionality and starting point, analogous to choosing a primary class in an ontology that has direct relationships to other classes, and from which one can navigate to the rest of the classes.
Adopting Venetian Blind pattern reduces the variability in its application and deems the schema usable in specific scenarios by providing not only well-defined elements, but also a rigid and predictable structure.
On the other hand, the Garden of Eden pattern allows for multiple global elements, providing various entry points into the XML document. This pattern accommodates ontologies where no single class is inherently central, mirroring the flexibility of graph representations in ontologies that do not have a strict hierarchical starting point.
Adopting the Garden of Eden pattern provides a less constrained approach, enabling users to represent information starting from different elements that may hold significance in different contexts. This approach has been adopted by standardisation initiatives such as NIEM [niem] and UBL [ubl], which recommend such flexibility for broader applicability and ease of information representation.
However, the Garden of Eden pattern does not lead to a schema that can be used in final application scenarios, because it does not ensure a single stable document structure but leaves the possibility for variations. This schema pattern requires an additional composition specification. For example, if it is used in a SOAP API [soap-api], the developers can decide on using multiple starting points to facilitate exchange of granular messages specific per API endpoint. This way the XSD schema remains reusable for different API endpoints and even API implementations.
Overall, the choice between these patterns should be informed by the intended use of the schema, the level of abstraction of the ontology it represents, and the needs of the end-users, aiming to strike a balance between structure and flexibility.
We consider the Garden of Eden pattern suitable for designing XSD schemas at the level of core or domain semantic data specifications, and the Venetian Blind pattern suitable for XSD schemas at the level of specific data exchange or API.
|
Recommendation for choosing the appropriate pattern: The Venetian Blind Pattern suits an API where a central entity is the main entry point, offering a structured schema for defined use cases. The Garden of Eden Pattern is better for Core or Domain Data Specifications, where multiple entry points provide flexibility for general-purpose data models. |
Complex types should be defined, if deemed necessary, only after importing or defining the basic elements and application of patterns. Complex types are deemed complex when they have multiple properties, be they attributes or relationships.
Finally, complete the XSD schema by adding annotations and documentation, which improve understanding of the schema’s content both for external users and oneself at a later date, as well as communicating the purpose so that the schema will be deployed as intended.
|
Add annotations and documentation using the |
Phase 3: Validation
The schema should be validated with at least one sample XML document, to verify that it is syntactically correct, semantically as intended, and that it has adequate coverage. SEMIC XSD schemas adhere to best practices and the resulting XSD schemas should also adhere to best practices, the SEMIC Style Guide, validation rules to maintain consistency, clarity, and reusability across schemas. These rules include naming conventions, documentation standards, and structural rules.
Having created the XML representation from the Core Vocabulary, we thus created a binding between the technical and semantic layer for the interoperability of the data. Either may possibly evolve over time and changes initiated from either direction should be consulted with the other, and may require re-validation of the binding. Strategies to avoid problematic divergence are to be put in place.
Tutorial: Create an XSD schema using the Core Business Vocabulary
Creating an XSD schema using the Core Business Vocabulary (CBV) involves defining the structure, data types, and relationships for the elements of the CBV, ensuring interoperability between systems. This tutorial follows the guidelines outlined for Use Case UC1.1 "Create a New XSD Schema", showing how to design and create an XSD schema that integrates terms from the Core Business Vocabulary (CBV). This step-by-step guide focuses on the essential phases of the schema creation process, ensuring that the elements from CBV are correctly imported, the document structure is shaped properly, and all constraints are applied.
To recap the process, we first will import or define elements, shape the structure with patterns, define complex types, and finalise the schema.
Phase 1: Import or define elements
Managing Imports and Namespaces
In XML Schema development, managing imports and namespaces is crucial to ensure that elements from external vocabularies are reused and integrated consistently. This step ensures that the schema obtains and maintains semantics, will be reusable, and is correctly aligned with the Core Business Vocabulary (CBV).
For example, CBV comes with its own XSD schema, the following import statement imports all definitions related to CBV elements into your XSD schema (explained afterwards):
<?xml version="1.0" encoding="UTF-8"?>
<xs:schema
xmlns:xs="http://www.w3.org/2001/XMLSchema"
targetNamespace="http://data.europa.eu/m8g/xsd"
xmlns="http://data.europa.eu/m8g/xsd"
xmlns:dct="http://purl.org/dc/terms/"
xmlns:sawsdl="http://www.w3.org/ns/sawsdl"
elementFormDefault="qualified"
attributeFormDefault="unqualified"
version="2.2.0">
<!-- Importing Core Business Vocabulary schema -->
<xs:import
namespace="http://data.europa.eu/m8g/"
schemaLocation="https://raw.githubusercontent.com/SEMICeu/XML-schema/refs/heads/main/models/CoreVoc_Business/CoreVoc_Business.xsd"/>
</xs:schema>The key components are:
-
<xs:import>: The element that imports the CBV schema to make its terms available in your schema. -
namespace="http://data.europa.eu/m8g/": Defines the namespace of the CBV. -
schemaLocation="https://raw.githubusercontent.com/SEMICeu/XML-schema/main/models/CoreVoc_Business/CoreVoc_Business.xsd": Points to the location of the CBV schema file on the Web.
Define elements
If the XSD schema of the CV does not suffice, in that you need additional elements beyond the XSD schema, then you have to define those yourself in the XSD schema you are developing. This might be an element from the CV associated with the XSD, or possibly elements from another CV or semantic artefact.
These new elements need to adhere to the Core Vocabulary’s namespace to maintain consistency.
For example, the LegalEntity element could be defined as follows if no XSD is provided for it:
<xs:element name="LegalEntity" type="LegalEntityType"/>Make sure you declare the correct namespace (e.g., http://example.com/) for all these custom elements.
Phase 2: Shape the XML document structure with patterns
At this phase, we focus on structuring the XML document using appropriate XML Schema Design Patterns [dsg-ptr]. The Venetian Blind and Garden of Eden patterns are two methods for organizing the schema.
Venetian Blind Pattern
In the Venetian Blind pattern, there is one primary global element, and all other elements are nested inside it. This approach is ideal when a central entity, such as LegalEntity, serves as the entry point, as seen in CBV’s XSD. This pattern fits well with API design, where you typically request information about a central concept (such as LegalEntity), and the response includes nested properties, including LegalName and RegisteredAddress, which are all organised under the main entity.
Here’s an example, where LegalEntity serves as the main entry point:
<xs:schema
targetNamespace="http://data.europa.eu/m8g/xsd"
xmlns="http://data.europa.eu/m8g/xsd"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:dct="http://purl.org/dc/terms/"
xmlns:sawsdl="http://www.w3.org/ns/sawsdl">
<xs:element name="LegalEntity" type="LegalEntityType"/>
<xs:element name="LegalName" type="TextType"/>
<xs:element name="RegisteredAddress" type="AddressType"/>
<!-- Other elements -->
</xs:schema>In this example:
-
LegalEntityis the global entry point. -
It uses
LegalEntityType, which contains various properties such asLegalNameandRegisteredAddress.
Garden of Eden Pattern
In the Garden of Eden pattern, there are multiple entry points in the XML document. This is more flexible and is suitable when no central class is inherently the main starting point. The elements that are declared directly under <xs:schema> qualify as such entry points. In CBV these include LegalEntity, Organization etc., whereas nested elements, such as RegisteredAddress or ContactPoint, are defined inside those complex types and cannot start a document on their own.
<xs:schema xmlns:xs="http://www.w3.org/2001/XMLSchema">
<xs:element name="LegalEntity" type="LegalEntityType"/>
<xs:element name="Organization" type="OrganizationType"/>
</xs:schema>Define Complex Types
After importing or defining the basic elements and structuring your XML document with patterns, the next step in creating an XSD schema is to define complex types. Complex types are used to represent business entities that contain multiple properties or relationships. For CBV, these types often model entities like LegalEntity or Organization, which have both simple and complex elements. For example, the LegalEntityType and OrganizationType, as follows.
An implemented LegalEntity might contain multiple child elements, such as LegalName modelled as a simple string, RegisteredAddress (also a complex type), and other related elements. Here’s how LegalEntityType is defined in the XSD schema:
<xs:complexType name="LegalEntityType"
sawsdl:modelReference="http://www.w3.org/ns/legal#LegalEntity">
<xs:sequence>
<xs:element
ref="LegalName"
minOccurs="0"
maxOccurs="unbounded"
sawsdl:modelReference="http://www.w3.org/ns/legal#legalName"/>
<xs:element
ref="RegisteredAddress"
minOccurs="0"
maxOccurs="unbounded"
sawsdl:modelReference="http://data.europa.eu/m8g/registeredAddress"/>
<!-- More elements as needed -->
</xs:sequence>
</xs:complexType>|
The sawsdl:modelReference annotation is used to link the element to an external concept, providing semantic context by associating the element with a specific vocabulary or ontology. |
Similar to the LegalEntityType complex type, the BusinessAgentType defines a concept with multiple properties and relationships. However, for BusinessAgentType in the XSD schema, we define it as a complex type that contains hierarchical relationships, such as HeadOf and MemberOf.
<xs:complexType name="BusinessAgentType"
sawsdl:modelReference="http://xmlns.com/foaf/0.1/Agent">
<xs:sequence>
<xs:element
ref="HeadOf"
minOccurs="0"
maxOccurs="unbounded"
sawsdl:modelReference="http://www.w3.org/ns/org#headOf">
</xs:element>
<xs:element
ref="MemberOf"
minOccurs="0"
maxOccurs="unbounded"
sawsdl:modelReference="http://www.w3.org/ns/org#memberOf">
</xs:element>
</xs:sequence>
</xs:complexType>It’s important to observe that in this context, LegalEntityType is defined as an extension of FormalOrganizationType (which, in turn, extends OrganizationType), declared using an <xs:extension base="…"> element, as shown in the following snippet.
<!-- LegalEntityType -->
<xs:element name="LegalEntity" type="LegalEntityType"/>
<xs:complexType name="LegalEntityType"
sawsdl:modelReference="http://www.w3.org/ns/legal#LegalEntity">
<xs:complexContent>
<xs:extension base="FormalOrganizationType"/>
</xs:complexContent>
</xs:complexType>Finalise the XSD schema
Adding annotations and documentation to each complex type and element helps to clarify their purpose and improve the readability of the schema. For instance:
<xs:complexType name="BusinessAgentType"
sawsdl:modelReference="http://xmlns.com/foaf/0.1/Agent">
<xs:annotation>
<xs:documentation xml:lang="en">
Entity that is able to carry out action.
</xs:documentation>
</xs:annotation>
</xs:complexType>Phase 3: Validation and best practices
Finally, test your new schema by validating sample XML documents using XML validation tools (e.g., XMLValidation) to ensure that the schema is syntactically correct and works as expected. The Core Business Vocabulary (CBV) follows several best practices and validation rules to maintain consistency, clarity, and reusability across schemas. These rules include naming conventions, documentation standards, and structural rules.
Schematron Validation Rules
To ensure schema compliance, the Schematron rules provide automated checks. These rules cover key aspects such as type definitions, element declarations, metadata, and more. The detailed list of rules can be found here.
Running the Validation
You can execute the rules using the provided build.xml file, which leverages Apache Ant. The process validates the schema against the Schematron rules and generates HTML reports for easy inspection.
Create a new JSON-LD context definition from a Core Vocabulary (UC1.2)
Use case description
Public administrations often need to share information about their services with other organisations and the public. To do this effectively, the data must be easy to understand and work seamlessly across different systems. However, public services are becoming more complex, which means we need to capture more details, concepts, and relationships to handle various use cases. This was also the case in Norway, which came to a fruitful solution. Let us imagine how that might have happened in the following scenario as motivation for the use case, which is followed by a user story that summarises it.
Consider Nora, who works for the DiTFor, the Norwegian Digitalisation Task Force. Although Norway is not a member of the EU, it is closely associated with the EU through its membership in the European Economic Area (EEA) and the Schengen Area. As part of the EEA, Norway participates in the EU’s internal market and adopts many EU laws and regulations. Therefore there is a lot of cross-border collaboration with other member states and there is a number of publicly available resources for use and reuse to facilitate interoperable exchange, including a vocabulary that could be used for their generic framework for their digitalisation of administration of public services: the Core Public Service Vocabulary Application Profile (CPSV-AP). They extended it to fit better with their context and needs, such as having introduced RequiredEvidence, which provides a way to explicitly define the documentation or credentials needed to access a service, such as proof of address for a library card. The extension was published publicly as CPSV-AP-NO.
Happy with the outcome, Nora emailed the municipalities so that each city and town would be able to upgrade their system in the same way with CPSV-AP-NO, and so that DiTFor could still collect and integrate the data at the national level.
Meanwhile, the City of Oslo’s transportation services department had just learned of smart data models to manage the data about public road network maintenance, such as dataModel.Transportation, and their helpdesk for reporting road maintenance issues. That data, stored according to the smart data model, could then also be used for the public transport network management organisation to work towards the aim to make Oslo a Smart City. A popular language to specify smart data models is a JSON-LD context, because it helps structure the data so it can be easily shared and understood by different systems.
The City of Oslo received DiTFor’s notification about the CPSV-AP-NO: their data models needed to comply with the CPSV-AP-NO for the purposes of effective use and interoperability. Looking into the details, they realised that it should be possible to utilise CPSV-AP-NO for their smart data model in JSON-LD and, in fact, would save them time looking for other vocabularies and adapting those. The question became one of how to do it, and so they replied to Nora’s email inquiring whether she could also provide instructions for using the Application Profile.
User Story: As a software engineer at a public sector department, I want to create a new JSON-LD context based on the Core Public Services Vocabulary Application profile (CPSV-AP), so that I can create interoperable smart data models that comply with national and European interoperability standards and support linked data publication to facilitate cross-system data exchange.
This business case translates into the following use case specification, which is instantiated from the general UC1.2 description in the previous section.
Use Case UC 1.2: Create a new JSON-LD context |
Goal: Create a new JSON-LD context that links to the CPSV-AP. |
Primary Actors: Semantic Engineer and Software Engineer |
Description: : Design and implement a new JSON-LD context definition for the transportation services department of Oslo that adheres to, and takes as input, the nationally relevant vocabulary of the CPSV-AP (i.e., CPSV-AP-NO). Carry out the task in a systematic way following an agreed-upon guideline.
|
Having established the who, what, and why, the next step is how to accomplish this. The semantic engineer specifies the guidelines for JSON-LD context development from a vocabulary, which makes it easier for the software engineer to implement it. The guideline is described in the next section.
Guidelines to create a new JSON-LD context definition
This section provides guidelines for addressing use case UC1.2.
JSON-LD is a W3C Recommendation for serialising Linked Data, combining the simplicity, power, and Web ubiquity of JSON with the concepts of Linked Data. Creating JSON-LD context definitions facilitates this synergy. This ensures that when data is shared or integrated across systems, it maintains its meaning and can be understood in the same way across different contexts. This guide describes how to create new JSON-LD contexts for existing Core Vocabularies.
The three key phases are:
-
Import or define elements
-
Shape structure
-
Review and validate
This is visualised in the following figure, together with key tasks and suggestions.

Phase 1: Import or define elements
When a Core Vocabulary has an associated JSON-LD context already defined, it is not only easy, but also advisable to directly import this context using the @import keyword. This enables seamless reuse and guarantees that any complex types or elements defined within the vocabulary are integrated correctly and transparently within new schemas.
In cases where the Core Vocabulary does not provide an JSON-LD context, it is necessary to create the corresponding field element definitions for the reused URIs, in three steps:
-
Gather all the terms from the selected Core Vocabulary that need to be included in the JSON-LD context.
-
Decide the desired structure of the JSON-LD file, by defining the corresponding keys, such as
Person.givenName. These new fields must adhere to the naming defined by the selected Core Vocabulary to maintain consistency. -
Assign URIs to keys. Each term in the JSON-LD context must be associated with a URI from an ontology that defines its meaning in a globally unambiguous way. Associate the URIs established in Core Vocabularies to JSON keys using the same CV terms.
The ones that are imported by the Core Vocabularies, shall be used as originally defined.
Example: importing an existing context.
{
"@context": {
"@import": "https://example.org/cpsv-ap.jsonld"
}
}Phase 2: Shape structure
Main shaping of the structure
Start with defining the structure of the context by relating class terms with property terms and then, if necessary, property terms with other classes.
Commence by creating a JSON structure that starts with a @context field. This field will contain mappings from one’s own vocabulary terms to other’s respective URIs. Continue by defining fields for classes and subfields for their properties.
If the JSON-LD context is developed with the aim of being used directly in an exchange specific to an application scenario, then aim to establish a complete tree structure that starts with a single root class. To do so, specify precise @type references linking to the specific class.
If the aim of the developed JSON-LD context is rather to ensure semantic correspondences, without any structural constraints, which is the case for core or domain semantic data specification, then definitions of structures specific to each entity type and its properties suffice, using only loose references to other objects.
Example: defining a class with properties.
{
"@context": {
"Service": "http://example.org/Service",
"Service.name": "http://purl.org/dc/terms/title"
}
}Design note: Flat vs scoped context disambiguation
When defining properties in a JSON-LD context, one has to consider how attribute names are disambiguated across different classes. Two main approaches can be adopted:
-
Flat context disambiguation. In this approach, and demonstrated in the previous example, each property is declared globally and identified by a fully qualified key (for example,
Service.name). This guarantees that each attribute is uniquely associated with its URI, even when the same property name appears in different classes. The flat approach is straightforward to generate automatically and ensures full disambiguation, which is why it is adopted by the SEMIC toolchain. However, it can result in less readable JSON structures, because the prefixed property names may appear verbose or repetitive. -
Scoped context disambiguation. A context can be defined per class, allowing property names such as name or description to be reused within each class-specific scope. This produces cleaner and more human-readable JSON but can be more complex to design and maintain. Scoped contexts often require explicit
@typedeclarations or additional range indicators to ensure that the correct mappings are applied during JSON-LD expansion.
The choice between flat or scoped contexts should be motivated by the expected use of the data. When contexts are generated automatically or used for large-scale data exchange, the flat approach offers simplicity and reliability. When contexts are manually authored or designed for human-facing APIs, scoped contexts may be preferable for improved readability, provided that their additional complexity is manageable.
Improvements to the structure
To meet wishes from API consumers, one may use aliasing of keywords, where a JSON-LD context element is given a more easily recognisable string.
One can also extend the context by reusing terms from Core Vocabularies, which can be achieved using the @import keyword if included as a whole. Also, single elements can be added, such as additional properties and mapping those to other vocabulary elements of other vocabularies.
Phase 3: Review and validate
First, one should review the created context against any prior requirements that may have been described: is all prospected content indeed included in the context?
Second, the syntax should be verified with a JSON-LD validator, such as JSON-LD Playground to ensure that the context is free of errors and all URLs used are operational.
Example: an error in the URL.
{
"@context": [
{ "@import": "https://invalid-url/cpsv-ap.jsonld" }
]
}Tutorial: Create a JSON-LD context from the CPSV-AP Core Vocabulary
This tutorial addresses the use case UC1.2, and will show how to create a JSON-LD context for an Application Profile that extends CPSV-AP with new concepts that are defined by reusing concepts from the Core Business Vocabulary (CBV), following ideas from CPSV-AP-NO.
Phase 1: Import or define elements
Since CPSV-AP provides an existing JSON-LD context, we can import it in our own JSON-LD context using the @import statement. For example, in case of CPSV-AP version 3.2.0, the context can be directly reused like this:
{
"@context": {
"@import": "https://raw.githubusercontent.com/SEMICeu/CPSV-AP/master/releases/3.2.0/context/cpsv-ap.jsonld"
}
}If a context does not exist, define the elements explicitly. For example, CPSV-AP uses specific terms such as PublicService and ContactPoint. These terms must be mapped to URIs.
{
"@context": {
"PublicService": "http://purl.org/vocab/cpsv#PublicService",
"ContactPoint": "http://data.europa.eu/m8g/ContactPoint"
}
}If a context needs to be extended, define the new elements explicitly. For example, if we need new terms (classes), such as Service and RequiredEvidence, which are not in CPSV-AP these terms must be mapped to URIs (the examples are inspired by CPSV-AP-NO):
{
"@context": {
"Service": "http://example.com/cpsvap#Service",
"RequiredEvidence": "http://example.com/cpsvap#RequiredEvidence"
}
}Once you’ve imported or defined the relevant terms, you need to structure your JSON-LD context to reflect the relationships between the classes and their properties. This allows you to describe public services and their details in a standardised and machine-readable format.
Let’s look at an example where we define a Service and some of its key properties, such as contactPoint, description, name and hasRequiredEvidence:
{
"@context": {
"@import": "https://raw.githubusercontent.com/SEMICeu/CPSV-AP/master/releases/3.2.0/context/cpsv-ap.jsonld",
"Service": "http://example.com/cpsvap#Service",
"Service.hasRequiredEvidence": {
"@id": "http://example.com/cpsvap#RequiredEvidence",
"@container": "@set"
},
"Service.description": {
"@id": "http://purl.org/dc/terms/description",
"@type": "http://www.w3.org/1999/02/22-rdf-syntax-ns#langString",
"@container": "@set"
},
"Service.name": {
"@id": "http://purl.org/dc/terms/title",
"@type": "http://www.w3.org/1999/02/22-rdf-syntax-ns#langString",
"@container": "@set"
},
"Service.contactPoint": {
"@id": "http://data.europa.eu/m8g/contactPoint",
"@type": "@id",
"@container": "@set"
}
}
}Explanation of JSON-LD keywords used:
-
@context: Defines the mapping between terms (e.g., PublicService) and their corresponding IRIs. -
@container: Specifies how values are structured. For instance,-
@set: Explicitly defines a property as an array of values. It ensures that even if the data includes just one value, it will still be treated as an array by JSON-LD processors. This makes post-processing of JSON-LD documents easier as the data is always in array form, even if the array only contains a single value
-
-
@id: Provides the unique identifier (IRI) for a term or property. -
@type: Specifies the type of a value, which is commonly used for linking to classes or data types. -
@import: Imports another JSON-LD context, allowing reuse of its terms.
Example of a simple service instance
After defining the context and structure, you can now describe an actual Service instance by referencing the terms you defined earlier.
Example scenario
Let’s assume a public administration offers a service called "Health Insurance Registration". This service allows citizens to register for health insurance, which requires certain documents (evidence) to complete the process. Citizens might need to contact the administration for guidance, and the service details should be structured in a way that makes it easy to share and integrate across systems.
To illustrate this, we need to create a JSON-LD context representation of this service, highlighting
-
The required evidence for registration (e.g., proof of address);
-
The service’s name and description for clarity;
-
Contact information for users who may need assistance.
Try this in the JSON-LD Playground here and then check your solution with the example below.
{
"@context": [
"https://raw.githubusercontent.com/SEMICeu/CPSV-AP/master/releases/3.2.0/context/cpsv-ap.jsonld"
],
"@id": "http://example.org/service/healthInsuranceRegistration",
"@type": "PublicService",
"PublicService.name": {
"@value": "Health Insurance Registration",
"@language": "en"
},
"PublicService.description": {
"@value": "A service for registering for health insurance.",
"@language": "en"
}
}Aliasing keywords for API compatibility (REST API example)
When working with REST APIs, it is often beneficial to alias certain JSON-LD keywords for simpler or more consistent representations in client applications. For example, you might alias JSON-LD’s @id to url and @type to type to make the data more intuitive for API consumers, especially when working with legacy systems or client-side frameworks that use specific naming conventions.
Example of aliasing keywords
{
"@context": {
"url": "@id",
"type": "@type",
"Service": "http://purl.org/vocab/cpsv#PublicService",
"Service.name": "http://purl.org/dc/terms/title",
"Service.description": "http://purl.org/dc/terms/description"
},
"url": "http://example.com/service/healthInsuranceRegistration",
"type": "Service",
"Service.name": "Health Insurance Registration",
"Service.description": "A service for registering for health insurance."
}In this example, url is an alias for @id and type is an alias for @type.
By aliasing these terms, the API responses are simplified and more familiar to the developers interacting with the service, especially if they are accustomed to a different JSON structure.
Extend the context by reusing terms from Core Vocabularies
To highlight the reuse of terms from existing CVs, we can import the Core Business Vocabulary (CBV) context alongside the CPSV-AP context to gain access to business-related terms. This step ensures that you can use the additional terms from CBV, such as LegalEntity, Organisation, and ContactPoint, to enrich your Service descriptions.
{
"@context": [
{
"@import": "https://raw.githubusercontent.com/SEMICeu/CPSV-AP/master/releases/3.2.0/context/cpsv-ap.jsonld"
},
{
"@import": "https://raw.githubusercontent.com/SEMICeu/Core-Business-Vocabulary/master/releases/2.2.0/context/core-business-ap.jsonld"
}
]
}Define additional properties from the Core Business Vocabulary
Add CBV terms to enhance the description of the Service entity by reusing existing concepts such as LegalEntity, which helps to specify who provided the service.
{
"@context": {
"Service.providedBy": {
"@id": "http://example.com/legal#providedBy",
"@type": "http://example.com/legal#LegalEntity"
},
"LegalEntity": "http://www.w3.org/ns/legal#LegalEntity"
}
}Map extended properties in a service instance
Use the extended properties to describe more aspects of Service instances. For example:
{
"@context": [
"https://raw.githubusercontent.com/SEMICeu/CPSV-AP/master/releases/3.2.0/context/cpsv-ap.jsonld",
"https://raw.githubusercontent.com/SEMICeu/Core-Business-Vocabulary/master/releases/2.2.0/context/core-business-ap.jsonld",
{
"ex": "http://example.org/"
}
],
"@id": "http://example.org/service/healthInsuranceRegistration",
"@type": "PublicService",
"PublicService.name": {
"@value": "Health Insurance Registration",
"@language": "en"
},
"PublicService.description": {
"@value": "A service for registering for health insurance.",
"@language": "en"
},
"ex:providedBy": {
"@id": "http://example.org/legalEntity/healthDepartment",
"@type": "LegalEntity"
}
}Final review and validation
Use a JSON-LD validator (there are online tools available, such as the JSON-LD Playground) to validate JSON-LD context and make sure there are no errors. They also offer visualisation features, noting that it can only be visualised if the syntax is correct. There is no standard for how RDF graphs are to be rendered, and therefore different visualisation tools will result in different JSON-LD diagram-based visualisations. Below are two examples generated from the same JSON-LD snippet, rendered by, JSON-LD Playground and :isSemantic, respectively.
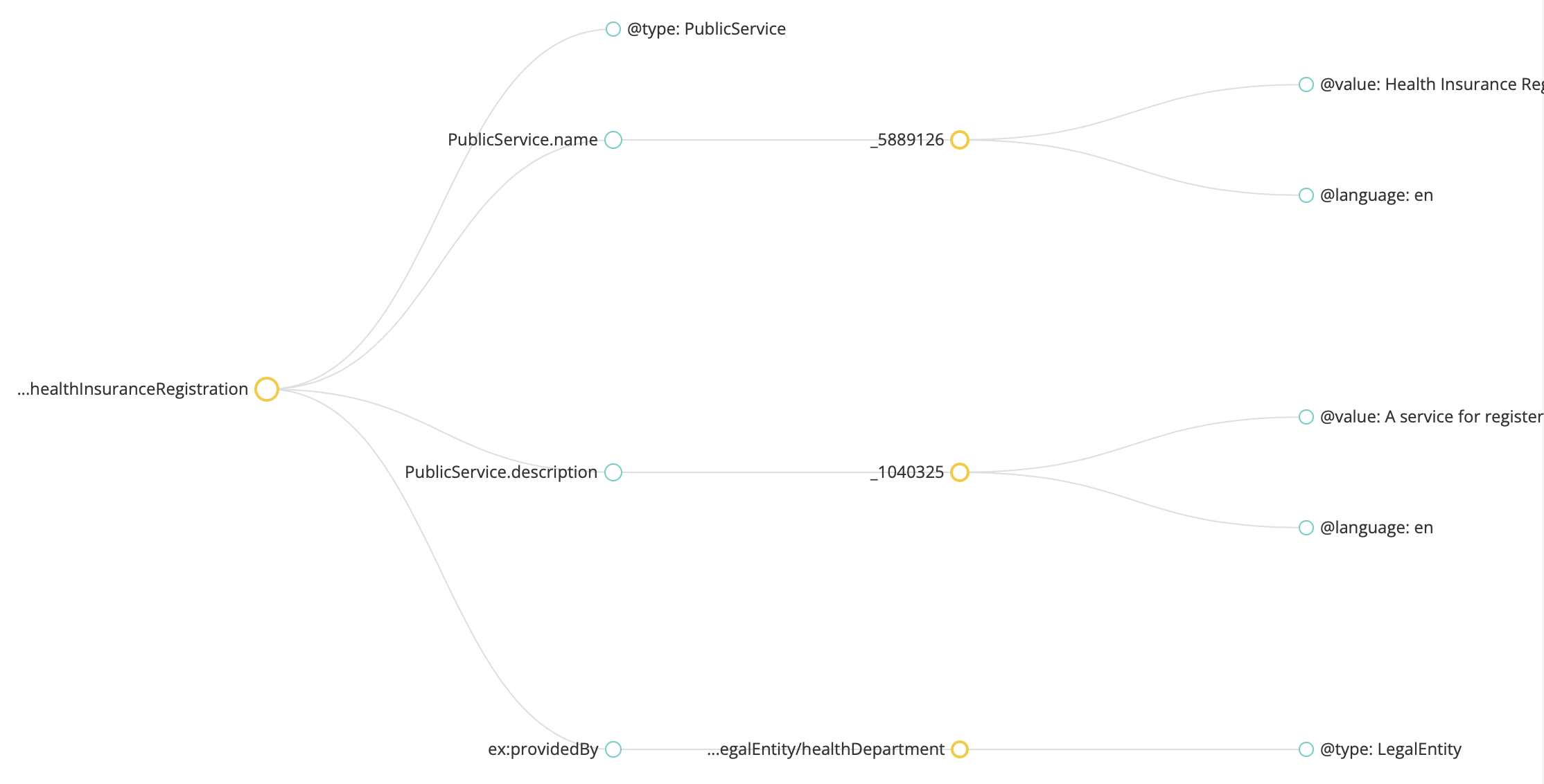
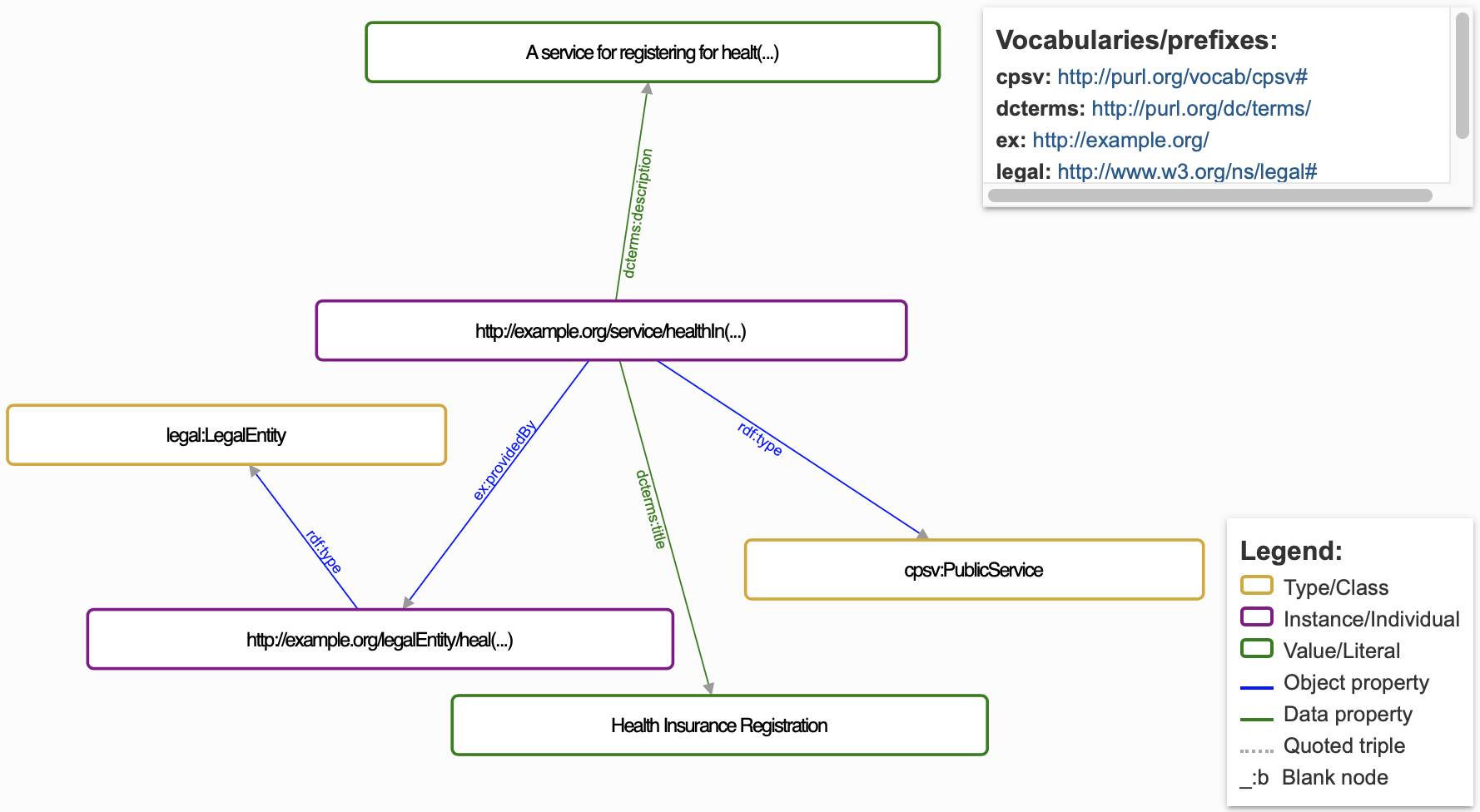
Error example
If the @import URLs for external contexts are incorrect or unavailable, the validation tool may display an error such as:
-
"Error loading remote context" or
-
"Context could not be retrieved."
{
"@context": [
{ "@import": "https://invalid-url/cpsv-ap.jsonld" }
]
}These errors typically occur when the referenced context URL is malformed or unreachable, as shown in the following figure:
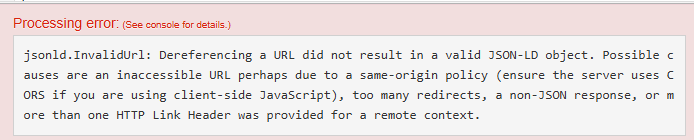
How to resolve the error
Ensure that the @import URLs point to valid and accessible JSON-LD contexts. Verify the links in a browser or test them in a cURL command to ensure they return the correct JSON-LD data (cURL is used in command lines or scripts to transfer data). Update the URLs to the correct ones.