Guidelines for Mapping an Existing XSD Schema
This section provides detailed instructions for addressing use case UC2.2.
In order to create an XSD mapping one needs to decide on the purpose and level of specificity of the XSD schema mapping. It can range from producing a lightweight alignment at the level of vocabulary down to a fully fledged executable set of rules for data transformation.
In this section we describe a methodology that covers both the conceptual mapping and the technical mapping for data transformation, and wrapping it up with validation and documentation.
Figure 1 depicts a workflow to create an XSD schema mapping, which is segmented into five phases:
-
Understand the XSD Schema and prepare test data, to ensure any preparations are completed before the mapping process;
-
Create a Conceptual Mapping, so that business and domain experts can validate the correspondences It involves defining the correspondence between the XML elements from the XSD schema and the terms in the vocabulary;
-
Create a Technical Mapping, so that the data can be automatically transformed. It involves converting the conceptual mappings into machine-executable transformation rules, focussing on the actual transformation of XML to RDF;
-
Validate the mapping rules to ensure consistency and accuracy;
-
Disseminate the documentation including, mainly, the used and generated files, mapping rules, and validation reports, to be applied in the foreseen use cases of the transformation pipelines.
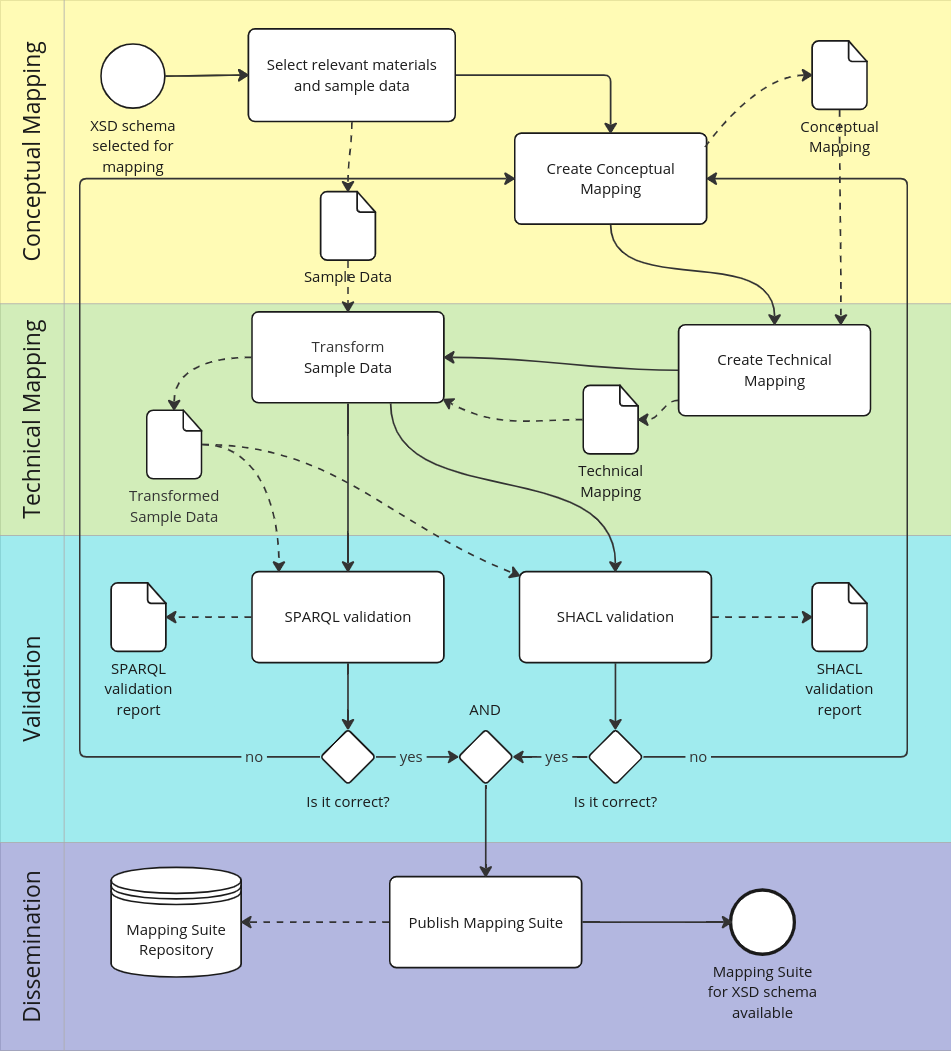
Figure 1. Workflow to create an XSD schema mapping
Phase 1: Understand XSD schema and prepare test data
Before initiating the mapping development process, it is crucial to construct a representative test dataset. This dataset should consist of a carefully selected set of XML files that cover the important scenarios and use cases encountered in the production data. It should be comprehensive yet sufficiently compact to facilitate rapid transformation cycles, enabling effective testing iterations in the validation phase. Also, it must align with the XSD schema for which it is test data.
Phase 2: Conceptual Mapping development
Conceptual Mapping in semantic data integration, i.e., regarding what from the source needs to map to what in the target, can be established at two distinct levels: the vocabulary level and the application profile level. These levels differ primarily in their complexity and specificity regarding the data context they address. We need to declare two mappings: regarding the vocabulary and the application profile.
A Vocabulary mapping mapping is established using basic XML elements. This form of mapping aims at a terminological alignment, meaning that an XML element or attribute is directly mapped to an ontology class or property. For example, an XML element <PostalAddress> could be mapped to locn:Address class in a Core Vocabulary, or an element <surname> could be mapped to a property foaf:familyName in the FOAF ontology. Such mappings can be established and written in a simple spreadsheet. This approach results in a basic 1:1 direct alignment, which lacks contextual depth and specificity.
A more advanced approach would be to embed semantic annotations into XSD schemas using standards such as SAWSDL. Such an approach is appropriate in the context of WSDL services.
The Application Profile mapping of the conceptual mapping utilises XPath to guide access to data in XML tree structures, enabling precise extraction and contextualization of data before mapping it to specific ontology fragments. An ontology fragment is usually expressed as a SPARQL Property Path (or simply: a Property Path). This Property Path facilitates the description of instantiation patterns specific to the Application Profile. This advanced approach allows for context-sensitive semantic representations, crucial for accurately reflecting the nuances in interpreting the meaning of data structures.
The tables below show two examples of mapping the organisation’s address, city and postal code. They show where the data can be extracted from, and how it can be mapped to targeted ontology properties such as locn:postName, and locn:postCode in the vocabulary. To ensure that this address is not mapped in a vacuum, but it is linked to an organisation instance, and not a person for example, the mapping is anchored in an instance ?this of an owl:Organisation. Optionally, a class path can be provided to complement the property path and explicitly state the class sequence, which otherwise can be deduced from the Application Profile definition.
| Source XPath | */efac:Company/cac:PostalAddress/cbc:PostalZone |
|---|---|
Target Property Path |
?this cv:registeredAddress /locn:postCode ?value . |
Target Class Path |
org:Organization / locn:Address / rdf:PlainLiteral |
| Source XPath | */efac:Company/cac:PostalAddress/cbc:CityName |
|---|---|
Target Property Path |
?this cv:registeredAddress / locn:postName ?value . |
Target Class Path |
org:Organization / locn:Address / rdf:PlainLiteral |
Inputs: XSD Schemas, Ontologies, SHACL Data Shapes, Source and Target Documentation, Sample XML data
Outputs: Conceptual Mapping Spreadsheet
Phase 3: Technical Mapping development
The technical mapping step is a critical phase in the mapping process, serving as the bridge between conceptual design and practical, machine-executable implementation. This step takes as input the conceptual mapping, which has been crafted and validated by domain experts or data-savvy business stakeholders and establishes correspondences between XPath expressions and ontology fragments.
When it comes to representing these mappings technically, several technology options are available (paper): such as XSLT, RML, SPARQLAnything, etc. But RDF Mapping Language (RML) stands out for its effectiveness and straightforward approach. RML allows for the representation of mappings from heterogeneous data formats like XML, JSON, relational databases and CSV into RDF, supporting the creation of semantically enriched data models. This code can be expressed in Turtle RML or the YARRRML dialect, a user-friendly text-based format based on YAML, making the mappings accessible to both machines and humans. RML is well-supported by robust implementations such as RMLMapper and RMLStreamer, which provide robust platforms for executing these mappings. RMLMapper is adept at handling batch processing of data, transforming large datasets efficiently. RMLStreamer excels in streaming data scenarios, where data needs to be processed in real-time, providing flexibility and scalability in dynamic environments.
The development of the mapping rules is straightforward due to the conceptual mapping that is already available from Phase 2. Then, RML mapping statements are created for each class of the target ontology coupled with the property-object mapping statements specific to that class. Furthermore, it is essential to master RML along with XML technologies such as XSD, XPath, and XQuery to implement the mappings effectively (rml-gen).
An additional step involves deciding on a URI creation policy and designing a uniform scheme for use in the generated data, ensuring consistency and coherence in the data output.
A viable alternative to RML is XSLT technology, which offers a powerful, but low-level method for defining technical mappings. While this method allows for high expressiveness and complex transformations, it also increases the potential for errors due to its intricate syntax and operational complexity. This technology excels in scenarios requiring detailed manipulation and parameterization of XML documents, surpassing the capabilities of RML in terms of flexibility and depth of transformation rules that can be implemented. However, the detailed control it affords means that developers must have a high level of expertise in semantic technologies and exercise caution and precision to avoid common pitfalls associated with its use.
A pertinent example of XSLT’s application is the tool for transforming ISO-19139 metadata to the DCAT-AP geospatial profile (GeoDCAT-AP) in the framework of INSPIRE and the EU ISA Programme. This XSLT script is configurable to accommodate transformation with various operational parameters such as the selection between core or extended GeoDCAT-AP profiles and specific spatial reference systems for geometry encoding, showcasing its utility in precise and tailored data manipulation tasks.
Inputs: Conceptual Mapping spreadsheet, sample XML data
Outputs: Technical Mapping source code, sample data transformed into RDF
Phase 4: Validation of the RDF output
Given the output of Phase 3 and the test data preparation from Phase 1, first transform the sample XML data into RDF, which will be used for validation testing. Two primary methods of validation are employed to ensure the integrity and accuracy of the data transformation: SPARQL-based validation and SHACL-based validation. They offer two fundamental methodologies for ensuring data integrity and conformity within semantic technologies, each serving distinct but complementary functions.
The SPARQL-based validation method utilises SPARQL ASK queries, which are derived from the SPARQL Property Path expressions (and complementary Class paths) created as part of the conceptual mapping phase. These expressions serve as assertions that test specific conditions or patterns within the RDF data corresponding to each conceptual mapping rule. By executing these queries, it is possible to confirm whether certain data elements and relationships have been correctly instantiated according to the mapping rules. The ASK queries return a boolean value indicating whether the RDF data meets the conditions specified in the query, thus providing a straightforward mechanism for validation. This confirms that the conceptual mapping is implemented correctly in a technical mapping rule.
For example, for the mapping rules above, the following assertions can be derived:
ASK {
?this a org:Organization .
?this cv:registeredAddress / locn:postName ?value .
}
ASK {
?this a org:Organization .
?this cv:registeredAddress / locn:postCode ?value .
}
The SHACL-based validation method provides a more comprehensive framework for validating RDF data. In this approach, data shapes are defined according to the constraints and structures expected in the RDF output, as specified by the mapped Application Profile. These shapes act as templates that the RDF data must conform to, covering various aspects such as data types, relationships, cardinality, and more. A SHACL validation engine processes the RDF data against these shapes, identifying any deviations or errors that indicate non-conformity with the expected data model.
SHACL is an ideal choice for ensuring adherence to broad data standards and interoperability requirements. This form of validation is independent of the manner in which data mappings are constructed, focusing instead on whether the data conforms to established semantic models at the end-state. It provides a high-level assurance that data structures and content meet the specifications designed to facilitate seamless data integration and interactions across various systems.
Conversely, SPARQL-based validation is tightly linked to the mapping process itself, offering a granular, rule-by-rule validation that ensures each data transformation aligns precisely with the expert-validated mappings. It is particularly effective in confirming the accuracy of complex mappings and ensuring that the implemented data transformations faithfully reflect the intended semantic interpretations, thus providing a comprehensive check on the fidelity of the mapping process.
Inputs: Sample data transformed into RDF, Conceptual Mapping, Technical Mapping, SHACL data shapes
Outputs: Validation reports
Phase 5: Dissemination
Once the conceptual and technical mappings have been completed and validated, they can be packaged for dissemination and deployment. The purpose of disseminating mapping packages are to facilitate their controlled use for data transformation, to ensure the ability to trace the evolution of mapping rules, and to standardise the exchange of such rules. This structured approach allows for efficient and reliable data transformation processes across different systems.
A comprehensive mapping package typically includes:
-
Conceptual Mapping Files: Serves as the core documentation, outlining the rationale and structure behind the mappings to ensure transparency and ease of understanding for both domain experts and engineers.
-
Technical Mapping Files: This contains all the mapping code files ( XSLT, RML, SPARQLAnything etc., depending on the chosen mapping technology) for data transformation, allowing for the practical application of the conceptual designs.
-
Additional Mapping Resources: Such as controlled lists, value mappings, or correspondence tables, which are crucial for the correct interpretation and application of the RML code. These should be stored in a dedicated resources subfolder.
-
Test Data Sets: Carefully selected and representative XML files that cover various scenarios and cases. These test datasets are crucial for ensuring that the mappings perform as expected across a range of real-world data.
-
Factory Acceptance Testing (FAT) Reports: They document the testing outcomes based on the SPARQL and SHACL validations to guarantee that the mappings meet the expected standards before deployment. The generation of these reports should be supported by automation, as manual generation would involve too much effort and costs.
-
Tests Used for FAT Reports: The package also incorporates the actual SPARQL assertions and SHACL shapes used in generating the FAT reports, providing a complete view of the validation process.
-
Descriptive Metadata: Contains essential data about the mapping package, such as identification, title, description, and versions of the mapping, ontology, and source schemas. This metadata aids in the management and application of the package.
This package is designed to be self-contained, ensuring that it can be immediately integrated and operational within various data transformation pipelines. The included components support not only the application, but also the governance of the mappings, ensuring they are maintained and utilised correctly in diverse IT environments. This systematic packaging addresses critical needs for usability, maintainability, and standardisation, which are essential for widespread adoption and operational success in data transformation initiatives.
Inputs: Conceptual Mapping spreadsheet, Ontologies or Vocabularies, SHACL Data Shapes, Sample XML data, Sample data transformed into RDF, Conceptual Mapping, Technical Mapping, SHACL data shapes, Validation reports
Outputs: Comprehensive Mapping Package